Search result for:
All Topics
Category
Research
Our picks

Long context models in the enterprise: benchmarks and beyond
Snorkel researchers devised a new way to evaluate long context models and address their “lost-in-the-middle” challenges with mediod voting.

Snorkel AI researchers present 18 papers at NeurIPS 2023
The Snorkel AI team will present 18 research papers and talks at the 2023 Neural Information Processing Systems (NeurIPS) conference from December 10-16. The Snorkel papers cover a broad range of topics including fairness, semi-supervised learning, large language models (LLMs), and domain-specific models. Snorkel AI is proud of its roots in the research community and endeavors to remain at the forefront…

Getting better performance from foundation models (with less data)
Getting better performance from foundation models (with less data)
Recomended for you
Benchmarks should shape the frontier, not just measure it
Since launching the Open Benchmarks Grants, we’ve received more than 100 applications from academic groups and industry labs spanning a wide range of domains and capabilities. Here, we share the new bar for useful benchmarks: what is now table stakes, and what separates the benchmarks that shape the frontier, not just measure it. Useful benchmarks are, first and foremost, effective…
Benchtalks #1: Alex Shaw (Terminal-Bench, Harbor) – Building the Benchmark Factory
To kick off our inaugural Benchtalks, a series dedicated to the researchers building these measurement toolkits, Snorkel AI co-founder Vincent Sunn Chen sat down with Alex Shaw, Founding MTS at Laude Institute and co-creator of Terminal-Bench and Harbor. Highlights More on Terminal-Bench: See the leaderboard and the catalog of tasks at tbench.ai. Explore Harbor: Learn how to scale your agent…
Building FinQA: An Open RL Environment for Financial Reasoning Agents
TL;DR: We built FinQA — a financial question-answering environment with 290 expert-curated questions across 22 public companies, now available on OpenEnv. Agents use MCP tools to discover schemas, write constrained SQL queries, and answer multi-step questions from real SEC 10-K filings. Most open-source models struggle with this kind of multi-step tool use, and even frontier closed-source models, while more accurate,…
All articles on
Research
Benchmarks should shape the frontier, not just measure it
Since launching the Open Benchmarks Grants, we’ve received more than 100 applications from academic groups and industry labs spanning a wide range of domains and capabilities. Here, we share the new bar for useful benchmarks: what is now table stakes, and what separates the benchmarks that shape the frontier, not just measure it. Useful benchmarks are, first and foremost, effective…

Benchtalks #1: Alex Shaw (Terminal-Bench, Harbor) – Building the Benchmark Factory
To kick off our inaugural Benchtalks, a series dedicated to the researchers building these measurement toolkits, Snorkel AI co-founder Vincent Sunn Chen sat down with Alex Shaw, Founding MTS at Laude Institute and co-creator of Terminal-Bench and Harbor. Highlights More on Terminal-Bench: See the leaderboard and the catalog of tasks at tbench.ai. Explore Harbor: Learn how to scale your agent…


Building FinQA: An Open RL Environment for Financial Reasoning Agents
TL;DR: We built FinQA — a financial question-answering environment with 290 expert-curated questions across 22 public companies, now available on OpenEnv. Agents use MCP tools to discover schemas, write constrained SQL queries, and answer multi-step questions from real SEC 10-K filings. Most open-source models struggle with this kind of multi-step tool use, and even frontier closed-source models, while more accurate,…

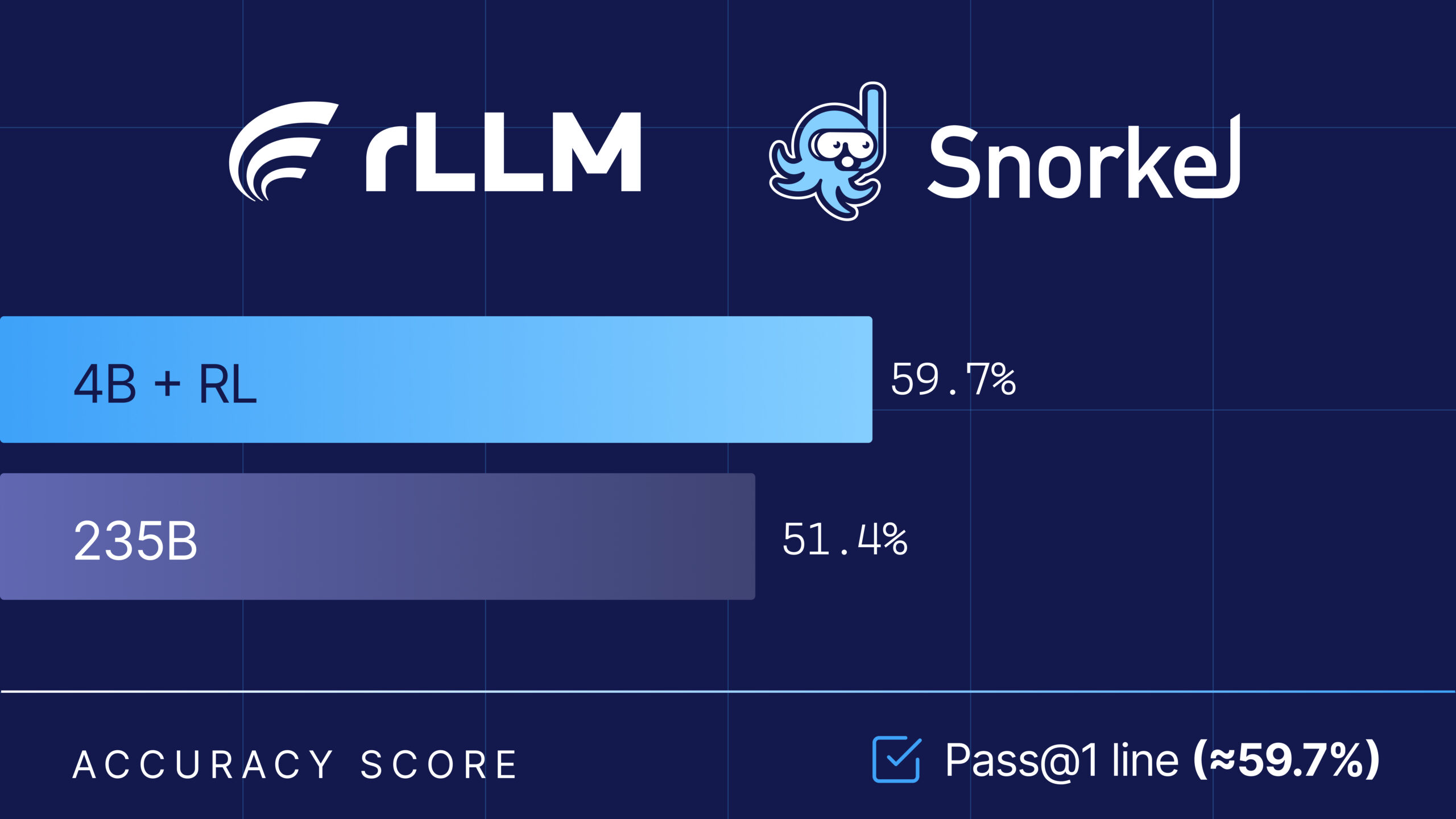
How Tool Discipline Let a 4B Model Outsmart a 235B Giant on Financial Tasks
The Snorkel research team collaborated with the rLLM team at UC Berkeley on the Agentica project, using their open-source rLLM framework to fine-tune Qwen3-4B-Instruct-2507, delivering a model that beats Qwen3-235B-A22B on Snorkel AI’s expert-curated financial benchmarks – at 1/60th the size. A full breakdown of the results are published in the rLLM blog here. The key insight? Just focus on…


Closing the Evaluation Gap in Agentic AI
Announcing a $3M commitment to launch Open Benchmarks Grants Today, AI is marked by a growing asymmetry: the excitement around agentic AI is real—backed by quantitative progress on model cards and genuine leaps forward, especially in coding. But ask individuals or enterprises where they feel ready to deploy agentic automation in high-stakes, domain-specific settings outside of coding… and you will…

Part V: Future direction and emerging trends
Explores how rubrics support agentic, multi-turn, tool-using, multimodal, and code-generating AI systems, and how they evolve with AI feedback and ensemble evaluation.


Chat with the Terminal-Bench team
Snorkel Chief Scientist Fred Sala and Kobie Crawford chat with the Terminal-Bench team to unpack the design behind Terminal-Bench 2.0 and the new Harbor framework.



Intelligence Per Watt: A New Metric for AI’s Future
Snorkel AI contributes specialized datasets to Hazy Research’s “Intelligence-per-Watt” study, advancing how efficiently AI turns energy into intelligence.

Snorkeling in RL environments
We unpack what makes a high-quality RL environment for LLMs and show how we build realistic, enterprise-grade environments at Snorkel AI.


Introducing SnorkelSpatial
A procedurally generated and programmatically verified benchmark for evaluating spatial reasoning capabilities in LLMs Large language models (LLMs) are showing remarkable results on solving complex reasoning problems across domains—from mathematical proofs and logical puzzles to graduate-level science and engineering questions. On the other hand, their spatial reasoning capabilities are less understood, even though such reasoning underlies many everyday tasks. We…


Scaling Trust: Rubrics in Snorkel’s Quality Process
Snorkel’s “Trusted Scale” philosophy Welcome to Part 4 of Snorkel AI’s rubric series. In previous posts, we explored how rubrics enable structured evaluation (Part 1), the spectrum of rubric types and use cases (Part 2), and the science behind designing and validating them (Part 3). In this latest installment, we pull back the curtain on how Snorkel puts these principles…


Evaluating Multi-Agent Systems in Enterprise Tool Use
In recent months, there has been increasing interest in the area of multi-agent systems and how they can be used to solve more complex tasks than a single agent could accomplish on its own. The topic is particularly interesting and raises several questions and ideas to consider: Anthropic’s blog post about how they architected a multi-agent deep research system is…

Evaluating Coding Agent Capabilities with Terminal-Bench: Snorkel’s Role in Building the Next Generation Benchmark
Terminal-Bench, developed through a collaboration between Stanford University and Laude Institute, has quickly become the gold standard benchmark for evaluating AI agent capabilities in a command line environment. This comprehensive evaluation framework measures how effectively AI agents can perform complex, real-world tasks within terminal environments. At Snorkel AI, we’re excited to share that we’re one of the top collaborators contributing…



Parsing Isn’t Neutral: Why Evaluation Choices Matter
Behind every AI benchmark is a hidden choice: how to read the model’s answers. That choice—parsing—can quietly tilt results more than the model itself. Parsing is where we take an AI system’s raw response and extract the “answer” we use for scoring. It sounds mechanical, but as our research shows, the choice of parser can dramatically change measured accuracy. In…

The science of rubric design
Part 3 of our rubric series explains the science of rubric design. We show why rubrics should be treated like models—structured, measured, and iterated—to maximize objective alignment and inter-rater agreement. Learn how to choose hierarchy and scale points, track agreement (IAA) and LLMAJ alignment, and refine with domain experts, with examples like PaperBench and HealthBench.


See how Snorkel can help you get up to:
100x
Faster data curation
40x
Faster model delivery
99%
Model accuracy