Category
Snorkel AI emerged from a research project, and we remain closely connected to the research community. Students and professors associated with the Snorkel project continue to publish academic papers that push the field forward, and the Snorkel AI research team integrates the most promising of those ideas into our platform.
Our picks

Getting better performance from foundation models (with less data)
Getting better performance from foundation models (with less data)
August 4, 2023
•

Snorkel AI researchers present 18 papers at NeurIPS 2023
The Snorkel AI team will present 18 research papers and talks at the 2023 Neural Information Processing Systems (NeurIPS) conference from December 10-16. The Snorkel papers cover a broad range of topics including fairness, semi-supervised learning, large language models (LLMs), and domain-specific models. Snorkel AI is proud of its roots in the research community and endeavors to remain at the forefront
October 31, 2023
•

All articles on Research

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 29, 2026
•
Snorkel Team

Agentic AI Evaluation: Closing the Gap with Better Benchmarks and Data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to
June 22, 2026
•
Snorkel Team

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 20, 2026
•

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 18, 2026
•

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 11, 2026
•
,
The Art and Science of Building Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents in realistic,
June 8, 2026
•
Snorkel Team

Benchtalks #2: The Future of Coding Benchmarks with John Yang (SWE-Bench, ProgramBench)
For our second Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with John Yang, a Stanford PhD student and creator of the SWE-bench franchise, SWE-smith, CodeClash, and most recently ProgramBench. Highlights More on ProgramBench: See the benchmark and the upcoming leaderboard at programbench.com. More from John Yang: Publications and writing at john-b-yang.github.io. Snorkel
May 21, 2026
•

Why Coding Agents Need Better Data, Evals, and Environments
Coding agents have moved from tab-complete to teammate. They autonomously inspect repositories, edit files, run commands, diagnose failures, and work through multi-step engineering tasks. That creates a harder reliability problem. A model that only suggests code is easy for a human to evaluate. A coding agent refactoring your repository and testing its own changes is much harder to supervise –
May 6, 2026
•

Benchmarks should shape the frontier, not just measure it
Since launching the Open Benchmarks Grants, we’ve received more than 100 applications from academic groups and industry labs spanning a wide range of domains and capabilities. As the best benchmarks have driven how the field allocates research effort, the bar for what counts as useful has risen. Here, we share what’s now table stakes for useful benchmarks, and what separates
April 6, 2026
•

Benchtalks #1: Alex Shaw (Terminal-Bench, Harbor) – Building the Benchmark Factory
To kick off our inaugural Benchtalks, a series dedicated to the researchers building these measurement toolkits, Snorkel AI co-founder Vincent Sunn Chen sat down with Alex Shaw, Founding MTS at Laude Institute and co-creator of Terminal-Bench and Harbor. Highlights More on Terminal-Bench: See the leaderboard and the catalog of tasks at tbench.ai. Explore Harbor: Learn how to scale your agent
March 31, 2026
•

Building FinQA: An Open RL Environment for Financial Reasoning Agents
TL;DR: We built FinQA — a financial question-answering environment with 290 expert-curated questions across 22 public companies, now available on OpenEnv. Agents use MCP tools to discover schemas, write constrained SQL queries, and answer multi-step questions from real SEC 10-K filings. Most open-source models struggle with this kind of multi-step tool use, and even frontier closed-source models, while more accurate,
March 30, 2026
•
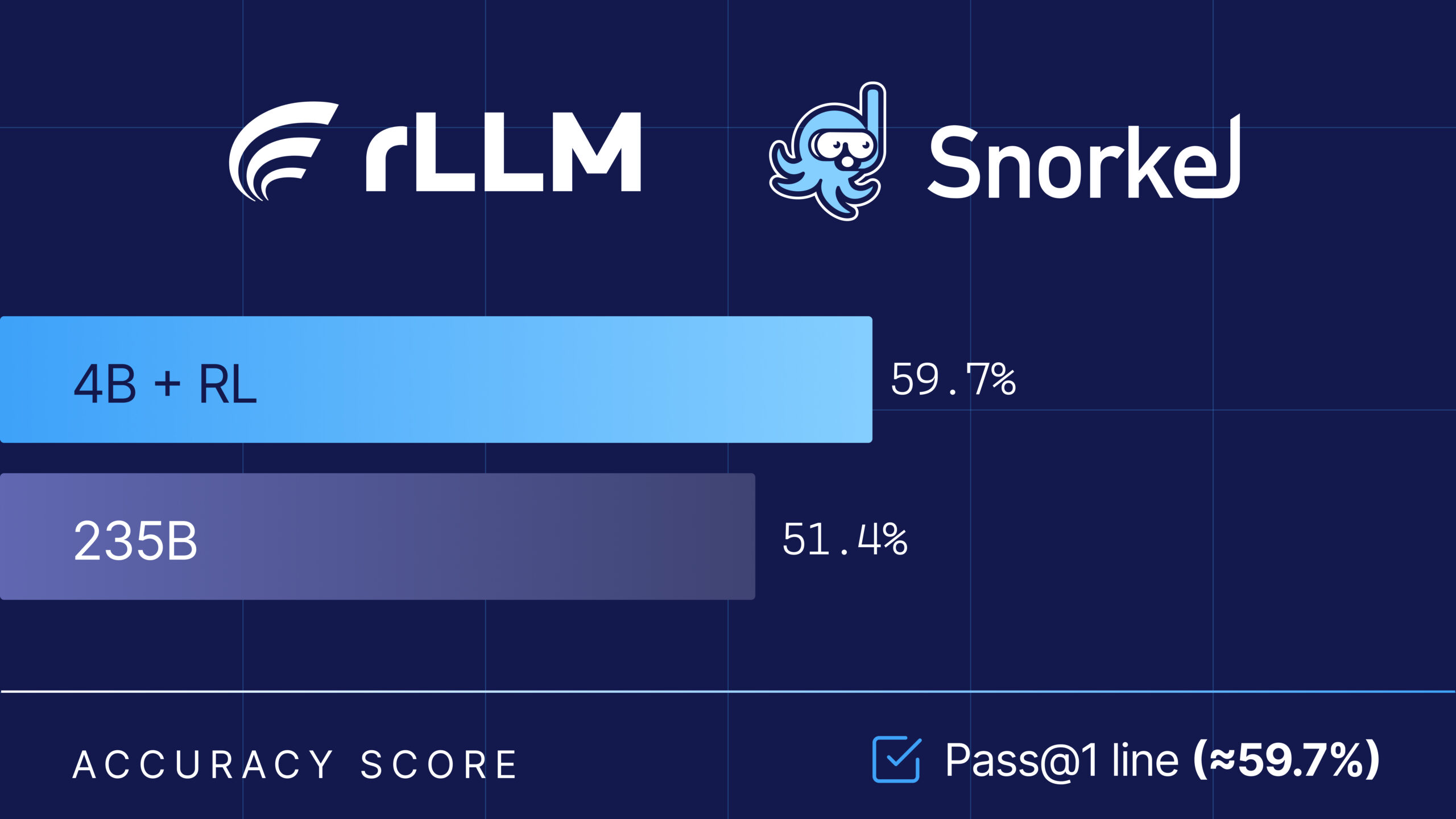
How Tool Discipline Let a 4B Model Outsmart a 235B Giant on Financial Tasks
The Snorkel research team collaborated with the rLLM team at UC Berkeley on the Agentica project, using their open-source rLLM framework to fine-tune Qwen3-4B-Instruct-2507, delivering a model that beats Qwen3-235B-A22B on Snorkel AI’s expert-curated financial benchmarks – at 1/60th the size. A full breakdown of the results are published in the rLLM blog here. The key insight? Just focus on
February 17, 2026
•

Closing the Evaluation Gap in Agentic AI
Announcing a $3M commitment to launch Open Benchmarks Grants Today, AI is marked by a growing asymmetry: the excitement around agentic AI is real—backed by quantitative progress on model cards and genuine leaps forward, especially in coding. But ask individuals or enterprises where they feel ready to deploy agentic automation in high-stakes, domain-specific settings outside of coding… and you will
February 11, 2026
•

