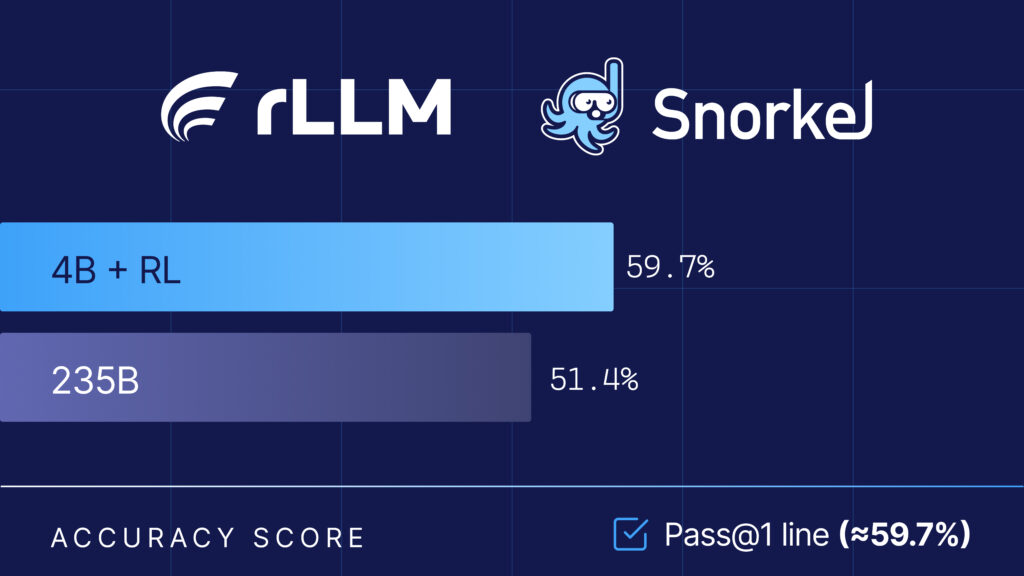
The Snorkel research team collaborated with the rLLM team at UC Berkeley on the Agentica project, using their open-source rLLM framework to fine-tune Qwen3-4B-Instruct-2507, delivering a model that beats Qwen3-235B-A22B on Snorkel AI’s expert-curated financial benchmarks – at 1/60th the size. A full breakdown of the results are published in the rLLM blog here.
The key insight? Just focus on tool use.
Why tool discipline beats scale
Large generalist models have excellent reasoning but poor tool discipline. They hallucinate column names, ignore constraints, and generate SQL that returns nonsensical results. The problem isn’t intelligence—it’s reliability.
Rather than training on expensive multi-table examples, the team focused on teaching reliable tool use with simple, single-table queries – and those skills generalized. In internal ablations, single-table-only training achieved the best results (66.3% internal Pass@1), outperforming both single + multi-table (61.6%) and a single→multi curriculum (64.8%).
The fundamentals generalize: explore tables before querying, validate data before proceeding, retry on failure rather than giving up.
Trained on simple tasks, verified in complex environments
The Snorkel team’s contributions were (1) the agentic environment for eval and RL, and (2) our FinQA-Reasoning dataset and Finance Reasoning benchmark, containing expert-curated financial analysis tasks for evaluating the agent’s performance, so we could be confident that the lift we saw was relevant to realistic, complex tasks. The rLLM team developed single-table queries that focused on using the relevant tools correctly, then completed the RL fine-tuning of the model under test in the environment.
Enterprise implications
The economics shift substantially. For a firm processing 50,000 analyst queries monthly, this approach could reduce costs by 90% while improving accuracy and keeping data on-premises. A 4B model runs on a single GPU; its 235B counterpart requires a multi-node cluster.
The methodology isn’t finance-specific either. Healthcare, legal, insurance – anywhere structured data and tool use intersect – the same pipeline applies: convert documents into queryable structures, teach tool-calling fundamentals on simple queries, verify aggressively, and fine-tune.
Build your own domain specialists
Qwen3-4B-Instruct-2507 was fine-tuned using the rLLM framework on a cluster of 8x H100 GPUs. By using small, specialized judges (GPT-5-nano) for simpler verifications and reserving larger models only for complex multi-table queries, the team kept the total training cost under $500 per run.
This fundamentally changes the accessibility of domain adaptation. You do not need a massive pre-training cluster to build a state-of-the-art specialist; instead, you need the right domain expertise, a well-engineered RL environment, and a smart verification pipeline.
The team is open-sourcing everything. Check out the rLLM blog here for links to their repository and the full details.
Snorkel is thrilled to have collaborated with Berkeley’s Sky Computing Lab and the rLLM team on this research project. For more details, check out their homepage here. For more information on how Snorkel can help you with RL environments and expert-curated datasets, come talk to us!

Chris Glaze
Principal Research Scientist
Experienced PhD with a demonstrated history of developing novel machine learning tools and mathematical models in academia and industry. Accomplishments span data mining, experimental research, and application to digital technologies.
Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 29, 2026
•
Snorkel Team

Agentic AI Evaluation: Closing the Gap with Better Benchmarks and Data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to
June 22, 2026
•
Snorkel Team

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 20, 2026
•

