Research
June 8, 2026
•
2 min read
•
Snorkel Team
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build benchmarks that move the field forward, not just measure it.
The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents in realistic, high-stakes settings has lagged behind. Closing that evaluation gap is one of the most important problems in AI right now — and open benchmarks are one of the most powerful levers available to address it.
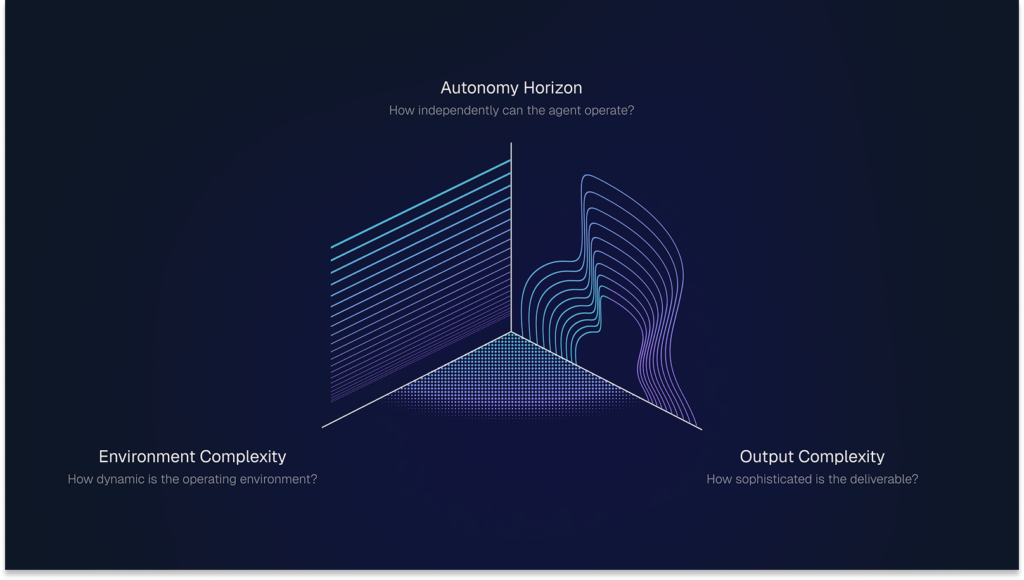
In the talk, Vincent breaks the problem into two halves. The first is the science of an effective measuring stick — rigorous task quality, deliberate distributional diversity, real model headroom, and a robust evaluation methodology — illustrated with benchmarks like GPQA, MMLU, ARC-AGI, and τ-bench. The second is the art that separates benchmarks that merely measure from the ones that reshape the field: a clear thesis on where things are going, a roadmap others can build on, and first-class researcher UX — think Terminal-Bench, SWE-bench, and HELM. The talk closes with a look at where the next great benchmarks may emerge: environment complexity, autonomy horizon, and output complexity.
If you want to go deeper than the talk, the two pieces below are the fuller written versions:
- For the framework: what makes a benchmark a useful measuring stick, and what makes one shape the frontier (Benchmarks should shape the frontier, not just measure it).
- For the forward-looking view: the three axes where tomorrow’s benchmarks need to push hardest (Closing the Evaluation Gap in Agentic AI).
And if any of this maps to what you’re building, the Open Benchmarks Grants are open: a $3M commitment to fund open benchmarks, datasets, and evaluation artifacts for frontier agents. Share a proposal or reach out at benchmarks.snorkel.ai.
Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 29, 2026
•
Snorkel Team

Agentic AI Evaluation: Closing the Gap with Better Benchmarks and Data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to
June 22, 2026
•
Snorkel Team

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 20, 2026
•

