
author
Chief Scientist
,
Snorkel AI
Assistant Professor @ University of Wisconsin-Madison
Frederic Sala is Chief Scientist at Snorkel AI and an assistant professor in the Computer Sciences Department at the University of Wisconsin-Madison. His research studies the fundamentals of data-driven systems and machine learning, with a focus on foundation models, automated machine learning, learning with limited data. Previously, he was a postdoctoral researcher at Stanford. He received his Ph.D. in electrical engineering from UCLA.
The latest from Fred

Blog
Chat with the Terminal-Bench team
Snorkel Chief Scientist Fred Sala and Kobie Crawford chat with the Terminal-Bench team to unpack the design behind Terminal-Bench 2.0 and the new Harbor framework.

Automating Benchmark Design
The rapid progress and widespread deployment of LLMs and LLM-powered agents has outpaced our ability to evaluate them. Hand-crafted, static benchmarks are the primary tool for assessing model capabilities, but these quickly become saturated. In contrast, dynamic benchmarks evolve alongside the models they evaluate, but are expensive to create and continuously update. To address these challenges, we develop BeTaL (Benchmark Tuning with an LLM-in-the-loop), a framework that leverages environment design principles to automate the process of dynamic benchmark design. BeTaL works by parameterizing key design choices in base benchmark templates and uses LLMs to reason through the resulting parameter space...
Research Paper
Accepted to ICLR 2026
Automating Benchmark Design
The rapid progress and widespread deployment of LLMs and LLM-powered agents has outpaced our ability to evaluate them. Hand-crafted, static benchmarks are the primary tool for assessing model capabilities, but these quickly become saturated. In contrast, dynamic benchmarks evolve alongside the models they evaluate, but are expensive to create and continuously update. To address these challenges, we develop BeTaL (Benchmark…
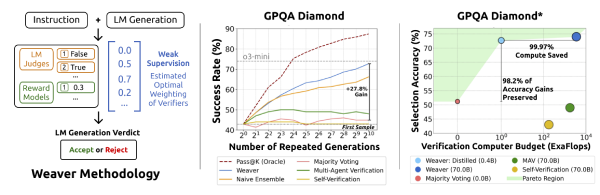
Shrinking the Generation-Verification Gap with Weak Verifiers
Verifiers can enhance language model (LM) performance by scoring and ranking a set of generated responses, but high-quality verifiers today are either unscalable (like human judges) or of limited practical use (such as formal proof tools like Lean). While LM-based judges and reward models serve as general-purpose verifiers, they still fall short of the performance levels achieved by oracle verifiers, which are perfectly accurate. To bridge this gap, the Weaver framework is introduced as a method for constructing a strong verifier by combining multiple weaker, imperfect ones. Weaver shows that weighted ensembles of verifiers, which traditionally depend on labeled data,...
Research Paper
Shrinking the Generation-Verification Gap with Weak Verifiers
Verifiers can enhance language model (LM) performance by scoring and ranking a set of generated responses, but high-quality verifiers today are either unscalable (like human judges) or of limited practical use (such as formal proof tools like Lean). While LM-based judges and reward models serve as general-purpose verifiers, they still fall short of the performance levels achieved by oracle verifiers,…
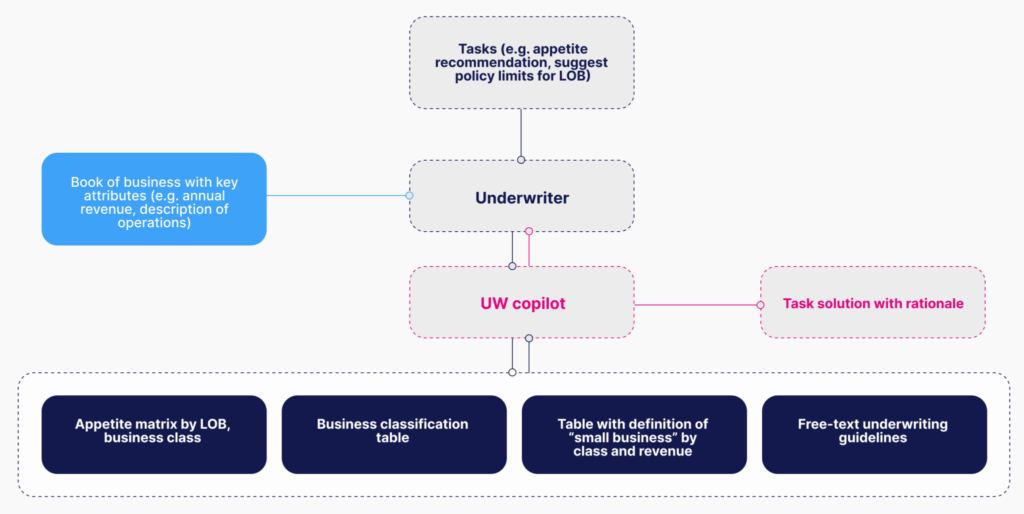
Blog
Building the Benchmark: Inside Our Agentic Insurance Underwriting Dataset
In this post, we unpack how Snorkel built a realistic benchmark dataset to evaluate AI agents in commercial insurance underwriting. From expert-driven data design to multi-tool reasoning tasks, see how our approach surfaces actionable failure modes that generic benchmarks miss—revealing what it really takes to deploy AI in enterprise workflows.
Weak-to-Strong Generalization Through the Data-Centric Lens
The weak-to-strong generalization phenomenon is the driver for important machine learning applications including highly data-efficient learning and, most recently, performing superalignment. While decades of research have resulted in numerous algorithms that produce strong empirical performance, understanding what aspects of data enable weak-to-strong generalization has been understudied. We propose a simple data-centric mechanism that characterizes weak-to-strong generalization: the overlap density. Intuitively, generalization tracks the number of points that contain overlaps, i.e., both easy patterns (learnable by a weak model) and challenging patterns (only learnable by a stronger model), as with such points, weak predictions can be used to learn challenging patterns...
Research Paper
Weak-to-Strong Generalization Through the Data-Centric Lens
The weak-to-strong generalization phenomenon is the driver for important machine learning applications including highly data-efficient learning and, most recently, performing superalignment. While decades of research have resulted in numerous algorithms that produce strong empirical performance, understanding what aspects of data enable weak-to-strong generalization has been understudied. We propose a simple data-centric mechanism that characterizes weak-to-strong generalization: the overlap density. Intuitively,…

Zero-Shot Robustification of Zero-Shot Models with Foundation Models
Zero-shot inference is a powerful paradigm that enables the use of large pretrained models for downstream classification tasks without further training. However, these models are vulnerable to inherited biases that can impact their performance. The traditional solution is fine-tuning, but this undermines the key advantage of pretrained models, which is their ability to be used out-of-the-box. We propose ROBOSHOT, a method that improves the robustness of pretrained model embeddings in a fully zero-shot fashion. First, we use zero-shot language models (LMs) to obtain useful insights from task descriptions. These insights are embedded and used to remove harmful and boost useful...
Research Paper
Zero-Shot Robustification of Zero-Shot Models with Foundation Models
Zero-shot inference is a powerful paradigm that enables the use of large pretrained models for downstream classification tasks without further training. However, these models are vulnerable to inherited biases that can impact their performance. The traditional solution is fine-tuning, but this undermines the key advantage of pretrained models, which is their ability to be used out-of-the-box. We propose ROBOSHOT, a…
The ALCHEmist: Automated Labeling 500x CHEaper Than LLM Data Annotators
Large pretrained models can be used as annotators, helping replace or augment crowdworkers and enabling distilling generalist models into smaller specialist models. Unfortunately, this comes at a cost: employing top-of-the-line models often requires paying thousands of dollars for API calls, while the resulting datasets are static and challenging to audit. To address these challenges, we propose a simple alternative: rather than directly querying labels from pretrained models, we task models to generate programs that can produce labels. These programs can be stored and applied locally, re-used and extended, and cost orders of magnitude less. Our system, Alchemist, obtains comparable to...
Research Paper
The ALCHEmist: Automated Labeling 500x CHEaper Than LLM Data Annotators
Large pretrained models can be used as annotators, helping replace or augment crowdworkers and enabling distilling generalist models into smaller specialist models. Unfortunately, this comes at a cost: employing top-of-the-line models often requires paying thousands of dollars for API calls, while the resulting datasets are static and challenging to audit. To address these challenges, we propose a simple alternative: rather…
Product Manifold Representations for Learning on Biological Pathways
Machine learning models that embed graphs in non-Euclidean spaces have shown substantial benefits in a variety of contexts, but their application has not been studied extensively in the biological domain, particularly with respect to biological pathway graphs. Such graphs exhibit a variety of complex network structures, presenting challenges to existing embedding approaches. Learning high-quality embeddings for biological pathway graphs is important for researchers looking to understand the underpinnings of disease and train high-quality predictive models on these networks. In this work, we investigate the effects of embedding pathway graphs in nonEuclidean mixed-curvature spaces and compare against traditional Euclidean graph representation...
Research Paper
Product Manifold Representations for Learning on Biological Pathways
Machine learning models that embed graphs in non-Euclidean spaces have shown substantial benefits in a variety of contexts, but their application has not been studied extensively in the biological domain, particularly with respect to biological pathway graphs. Such graphs exhibit a variety of complex network structures, presenting challenges to existing embedding approaches. Learning high-quality embeddings for biological pathway graphs is…
Pretrained Hybrids with MAD Skills
While Transformers underpin modern large language models (LMs), there is a growing list of alternative architectures with new capabilities, promises, and tradeoffs. This makes choosing the right LM architecture challenging. Recently-proposed hybrid architectures seek a best-of-all-worlds approach that reaps the benefits of all architectures. Hybrid design is difficult for two reasons: it requires manual expert-driven search, and new hybrids must be trained from scratch. We propose Manticore, 1 a framework that addresses these challenges. Manticore automates the design of hybrid architectures while reusing pretrained models to create pretrained hybrids. Our approach augments ideas from differentiable Neural Architecture Search (NAS) by...
Research Paper
Pretrained Hybrids with MAD Skills
While Transformers underpin modern large language models (LMs), there is a growing list of alternative architectures with new capabilities, promises, and tradeoffs. This makes choosing the right LM architecture challenging. Recently-proposed hybrid architectures seek a best-of-all-worlds approach that reaps the benefits of all architectures. Hybrid design is difficult for two reasons: it requires manual expert-driven search, and new hybrids must…
