
author
Research Fellow & Founding Team
,
Snorkel AI
Vincent Sunn Chen is a Research Fellow on the founding team at Snorkel AI. His work centers on systems for high quality AI evaluation & data development with experts in the loop. He currently leads the Open Benchmarks Grants, a $3M commitment to funding benchmarks and infrastructure for frontier agents. Prior to Snorkel, Vincent was a researcher at the Stanford AI Lab, where he studied the foundations of data-centric AI systems.
The latest from Vincent

Blog
Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration…

Blog
Benchtalks #2: The Future of Coding Benchmarks with John Yang (SWE-Bench, ProgramBench)
For our second Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with John Yang, a Stanford PhD student and creator of the SWE-bench franchise, SWE-smith, CodeClash, and most recently ProgramBench. Highlights More on ProgramBench: See the benchmark and the upcoming leaderboard at programbench.com. More from John Yang: Publications and writing at john-b-yang.github.io. Snorkel…

Blog
Benchmarks should shape the frontier, not just measure it
Since launching the Open Benchmarks Grants, we’ve received more than 100 applications from academic groups and industry labs spanning a wide range of domains and capabilities. As the best benchmarks have driven how the field allocates research effort, the bar for what counts as useful has risen. Here, we share what’s now table stakes for useful benchmarks, and what separates…

Blog
Benchtalks #1: Alex Shaw (Terminal-Bench, Harbor) – Building the Benchmark Factory
To kick off our inaugural Benchtalks, a series dedicated to the researchers building these measurement toolkits, Snorkel AI co-founder Vincent Sunn Chen sat down with Alex Shaw, Founding MTS at Laude Institute and co-creator of Terminal-Bench and Harbor. Highlights More on Terminal-Bench: See the leaderboard and the catalog of tasks at tbench.ai. Explore Harbor: Learn how to scale your agent…

Blog
Closing the Evaluation Gap in Agentic AI
Announcing a $3M commitment to launch Open Benchmarks Grants Today, AI is marked by a growing asymmetry: the excitement around agentic AI is real—backed by quantitative progress on model cards and genuine leaps forward, especially in coding. But ask individuals or enterprises where they feel ready to deploy agentic automation in high-stakes, domain-specific settings outside of coding… and you will…
Blog
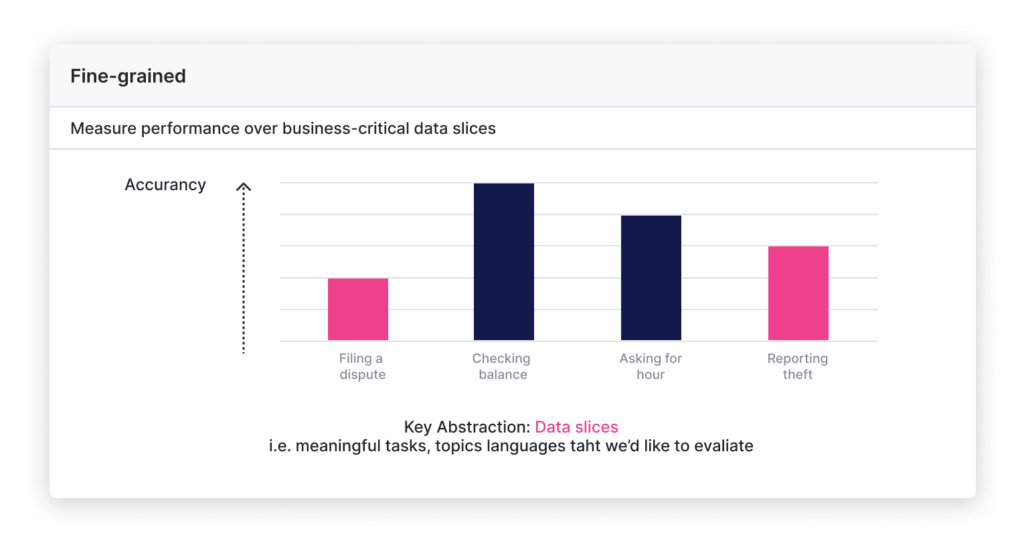
How data slices transform enterprise LLM evaluation
Enterprises must evaluate LLM performance for production deployment. Custom, automated eval + data slices present the best path to production.

Blog
How to tackle advanced classification challenges using Snorkel Flow
When done right, advanced classification applications cultivate business value and automation, unlock new business lines, and reduce costs.
Blog
Design Principles for Iteratively Building AI Applications
Enabling iterative development workflows with Snorkel Flow’s Application Studio. Consider this scenario— we’re AI engineers, and we’re building a social media monitoring application to track the sentiment of Fortune 500 company mentions in the news.
Slice-Based Learning: A Programming Model for Residual Learning
Proposing Slice-based Learning, a new programming model in which the slicing function (SF), a programmer abstraction, is used to specify additional model capacity for each slice.
Research Paper
Slice-Based Learning: A Programming Model for Residual Learning
Proposing Slice-based Learning, a new programming model in which the slicing function (SF), a programmer abstraction, is used to specify additional model capacity for each slice.
