We define and advance data and environments to push the AI frontier
building benchmarks and collaborating with
Featured research
Vision and impact
We help labs advance frontier models by working with domain experts to design and build complex, realistic datasets that drive model performance.
Benchmarking &
Evaluation
Build benchmarks that define and advance the AI frontier
Scaling Subject Matter Expertise
Define how subject matter experts encode their knowledge into data
RL, Training, & Data Valuation
Drive dataset development based on feedback from RL and model training
Community and open science
Open benchmarks, conversations, and research for real-world AI performance.

Open Benchmarks Grants
Backed by a $3M commitment, the program funds open-source datasets, benchmarks, and evaluation artifacts that shape how frontier AI systems are built and evaluated.

Bench Talks

Reading Group
DEEP RESEARCH Expertise
Technical advisors and distinguished affiliates









Browse research blogs and academic papers

Coding agents have moved from tab-complete to teammate. They autonomously inspect repositories, edit files, run commands, diagnose failures, and work through multi-step engineering tasks. That creates a harder reliability problem. A model that only suggests code is easy for a human to evaluate. A coding agent refactoring your repository and testing its own changes is much harder to supervise –…

Since launching the Open Benchmarks Grants, we’ve received more than 100 applications from academic groups and industry labs spanning a wide range of domains and capabilities. As the best benchmarks have driven how the field allocates research effort, the bar for what counts as useful has risen. Here, we share what’s now table stakes for useful benchmarks, and what separates…

To kick off our inaugural Benchtalks, a series dedicated to the researchers building these measurement toolkits, Snorkel AI co-founder Vincent Sunn Chen sat down with Alex Shaw, Founding MTS at Laude Institute and co-creator of Terminal-Bench and Harbor. Highlights More on Terminal-Bench: See the leaderboard and the catalog of tasks at tbench.ai. Explore Harbor: Learn how to scale your agent…

TL;DR: We built FinQA — a financial question-answering environment with 290 expert-curated questions across 22 public companies, now available on OpenEnv. Agents use MCP tools to discover schemas, write constrained SQL queries, and answer multi-step questions from real SEC 10-K filings. Most open-source models struggle with this kind of multi-step tool use, and even frontier closed-source models, while more accurate,…
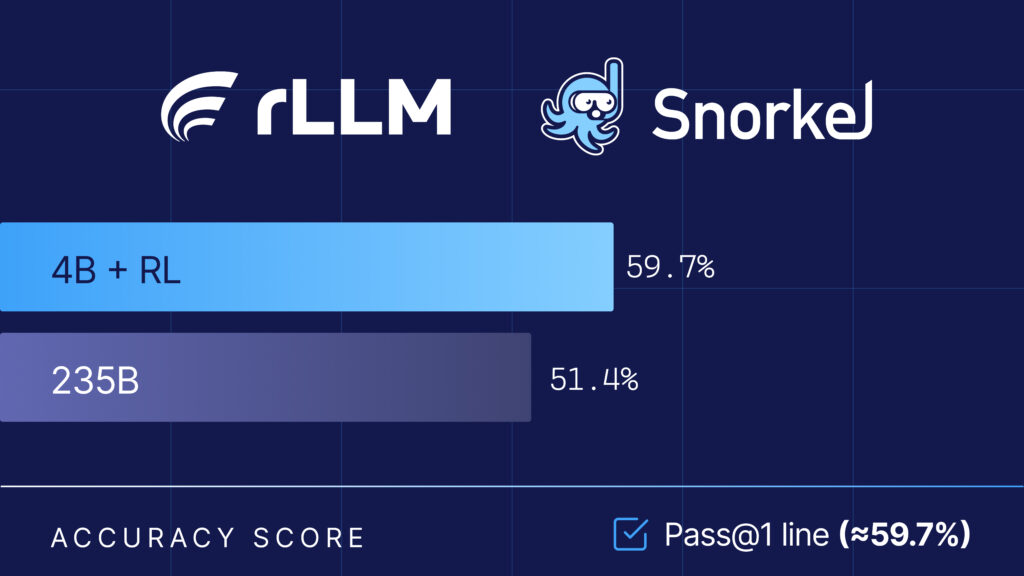
The Snorkel research team collaborated with the rLLM team at UC Berkeley on the Agentica project, using their open-source rLLM framework to fine-tune Qwen3-4B-Instruct-2507, delivering a model that beats Qwen3-235B-A22B on Snorkel AI’s expert-curated financial benchmarks – at 1/60th the size. A full breakdown of the results are published in the rLLM blog here. The key insight? Just focus on…

Announcing a $3M commitment to launch Open Benchmarks Grants Today, AI is marked by a growing asymmetry: the excitement around agentic AI is real—backed by quantitative progress on model cards and genuine leaps forward, especially in coding. But ask individuals or enterprises where they feel ready to deploy agentic automation in high-stakes, domain-specific settings outside of coding… and you will…

AI agents may soon become capable of autonomously completing valuable, longhorizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each…

Explores how rubrics support agentic, multi-turn, tool-using, multimodal, and code-generating AI systems, and how they evolve with AI feedback and ensemble evaluation.

Snorkel Chief Scientist Fred Sala and Kobie Crawford chat with the Terminal-Bench team to unpack the design behind Terminal-Bench 2.0 and the new Harbor framework.
